


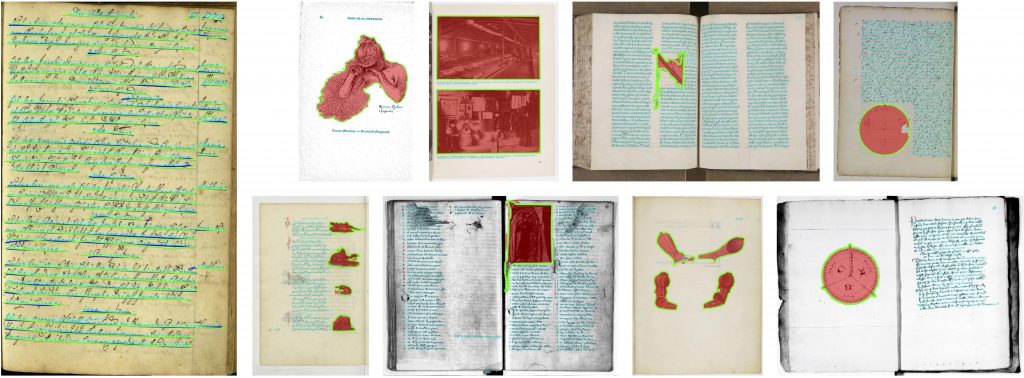
We designed an algorithm to automatically extract relevant elements in archive documents, such as text and images. We also built a website to allow non expert to perform extractions on any IIIF document, which unfortunately is not maintained anymore.
The main idea, that we further use in follow up EIDA and VHS tools is to train from synthetic documents a segmentation or detection algorithm. In the latest developments, we prefer detection algorithms, such as YOLO, which are better suited to pages with many and potentially overlapping illustrations.
Publications:
docExtractor: An off-the-shelf historical document element extraction
Tom Monnier and Mathieu Aubry, International Conference on Frontiers of Handwriting Recognition (ICFHR) 2020
PDF, webpage, code, demo